Portfolio

ChunkTuner
Benchmark chunking on your documents. Get a recommended config.
ChunkTuner runs your corpus through multiple chunking strategies, scores each with retrieval metrics (token recall, MRR, NDCG), optional RAGAS generation metrics, and LiteLLM-backed embeddings — with results cached in SQLite so you can iterate before you spend on embeddings.
The problem
If you have a corpus and a RAG stack, choosing chunking parameters and a strategy is usually guesswork. The wrong chunk size or splitter causes retrieval to fail on straightforward questions — not because the answer is missing, but because it sits across chunk boundaries. Most teams never score that decision against retrieval metrics or cost before they wire it into production.
ChunkTuner closes that gap: you get a recommended configuration backed
by token recall, MRR, NDCG, and related signals — plus cost awareness
(chunk-tune estimate) before any paid embedding call. If
you live in an MCP-capable assistant, you can preview chunks and
recommend a config without leaving the agent loop; if you need batch
evaluation in Python, the same core library drives your CI or eval
platform.
How it fits together
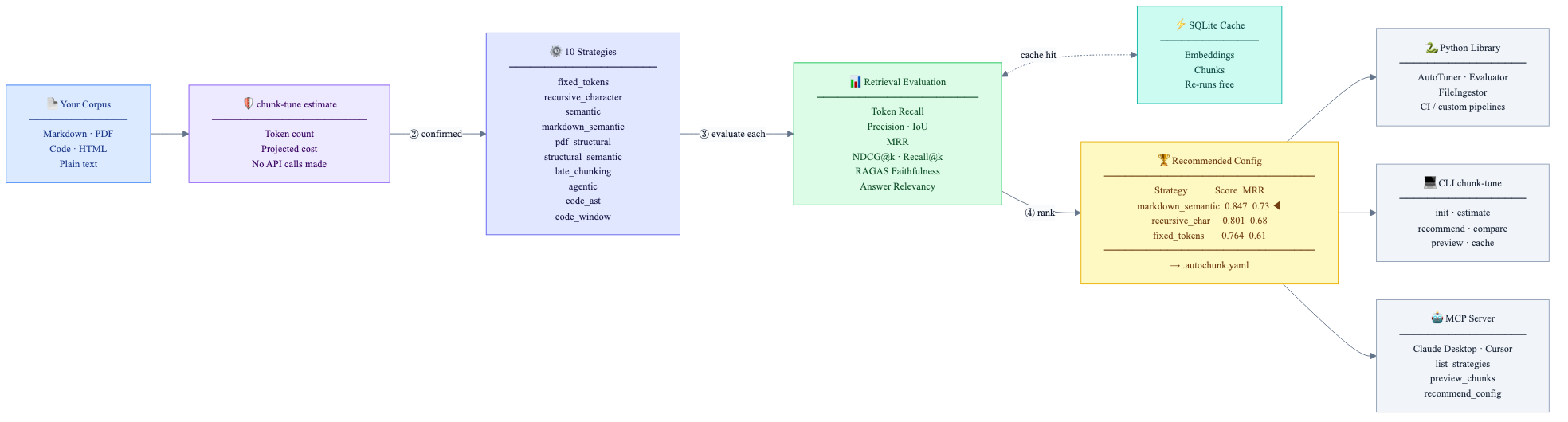
LangChain and LlamaIndex give you splitters; ChunkTuner benchmarks them on your documents and tells you which setup wins for your embedding model and use case. It does not replace RAGAS — it can integrate it — but it does run the multi-strategy loop those stacks do not ship out of the box.
What it does
ChunkTuner ingests a corpus, benchmarks it across ten chunking
strategies (fixed tokens, recursive character, semantic,
Markdown-aware, PDF structural, late chunking, agentic, code AST /
window, and more — each with a tunable parameter grid), then scores
configurations with retrieval metrics: token recall, MRR, NDCG@k,
precision, IoU, duplication, and chunk-length signals. Optional RAGAS
extras add faithfulness and answer relevancy. You get a ranked table
and the winner written to .autochunk.yaml for downstream pipelines.
Three interfaces share one core: a Python library for eval
and automation, a CLI (chunk-tune: init,
analyze, estimate, evaluate,
recommend, compare, preview,
cache), and an MCP server (chunk-tune-mcp, stdio FastMCP) so Claude Desktop, Cursor, and other MCP hosts can
list strategies, preview chunks, evaluate, and recommend from the
agent loop.
Three-command quickstart
# 1. Install
uv tool install chunktuner
# 2. Dry-run: token count and cost estimate (no paid API call)
chunk-tune estimate ./my_docs --use-case rag_qa
# 3. Run: evaluate strategies, get the winner
chunk-tune recommend ./my_docs --use-case rag_qa --embedding-model text-embedding-3-small estimate is always free. recommend charges only
for embeddings your provider bills; vectors live in a local SQLite cache
under
~/.cache/chunktuner, so re-runs on the same corpus are
cheap.
Trust and positioning
- Dry-run first.
chunk-tune estimatecounts tokens and projects cost before any cloud embedding call. - Caching. Embeddings (and chunk artifacts) are cached locally; iteration does not re-pay for unchanged corpora.
- MCP sandbox. Paths must resolve under
CHUNK_TUNER_BASE_DIR; the server does not ship your documents to remote infrastructure. - Optional extras. Docling, RAGAS, semantic, and code stacks are opt-in extras so the base install stays light.
ChunkTuner benchmarks; it does not promise SOTA on every corpus. The differentiation is a unified evaluation loop across many strategies and three surfaces (library, CLI, MCP), with cost transparency and reproducible commands documented on GitHub Pages.
Technical highlights
- Cost estimation before any paid call. The
estimatecommand is a full dry-run: it counts tokens, projects embedding cost per provider, and exits without making a single API call. This was a deliberate first-class feature — not a warning label. - SQLite-backed dual cache. Embedding vectors and chunk
results are persisted in two SQLite-backed caches. Re-running
recommendon the same corpus re-uses cached embeddings, making iteration free after the first run. - Provider-agnostic embeddings via LiteLLM. Any embedding
model — OpenAI, Cohere, Ollama, Mistral — works through a single
LiteLLMEmbeddingFunctioninterface. Tests use aDummyEmbeddingFunction(deterministic, zero cost) so the entire evaluation pipeline runs in CI without any API keys. - Protocol-based strategy registry. Each chunking strategy
implements a
ChunkingStrategyProtocol with a strict offset invariant:doc.content[chunk.start_offset:chunk.end_offset] == chunk.text. This invariant is tested for every strategy. New strategies can be added in a single file without touching the evaluator or tuner. - Parallel grid search. AutoTuner evaluates strategy ×
parameter-grid combinations via
ProcessPoolExecutor, keeping worker processes isolated from the main process's cache state. - MCP security model. The MCP server validates every file
path argument against
CHUNK_TUNER_BASE_DIR— an environment-variable-configured sandbox. Paths outside it are rejected immediately. No document content is logged; only document IDs and token counts. - Optional extras architecture. Heavy dependencies (docling for PDF/DOCX, ragas, semchunk for semantic strategies, tree-sitter for code AST) are fully optional. The base install is lightweight; users add only what their corpus type requires.
Stack
Python 3.10 · Pydantic v2 · Typer · FastMCP (MCP SDK) · LiteLLM · RAGAS · Docling · tree-sitter · tiktoken · SQLite · FastAPI · MkDocs · uv · Ruff · pytest · GitHub Actions (CI + PyPI publish + docs deploy)
Scale and completeness
- Ten chunking strategies with default parameter grids and strategy-guide guidance on when (and when not) to use each
- MkDocs site on GitHub Pages: quickstart, strategy guide, metrics reference, CLI and Python API references, MCP setup, and integration-oriented guides
-
PyPI package with optional extras (
mcp,docling,ragas,semantic,code,all) - CI: lint, typecheck, tests on Python 3.10–3.12, docs build, tagged PyPI publish
- Community scaffolding: issue templates, contributing notes, changelog, and roadmap for release cadence
Retrieval quality is not something you infer from a blog-post chunk size — you measure it on your corpus and embedding model. ChunkTuner is built so you can start with a free
estimate, run a scoredrecommend, and wire the winner into LangChain, LlamaIndex, or your own stack — from the terminal, from Python, or from an MCP assistant.